
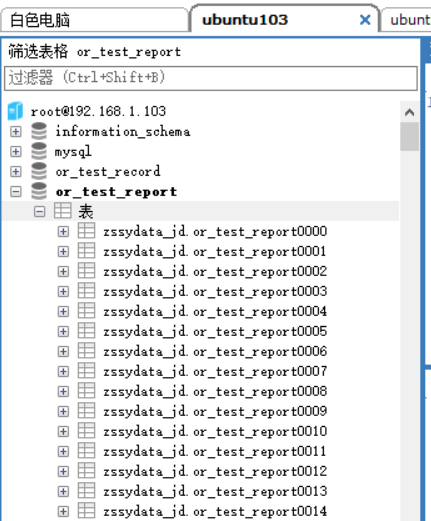
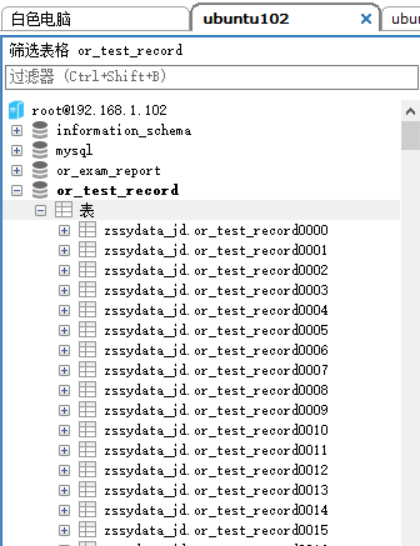
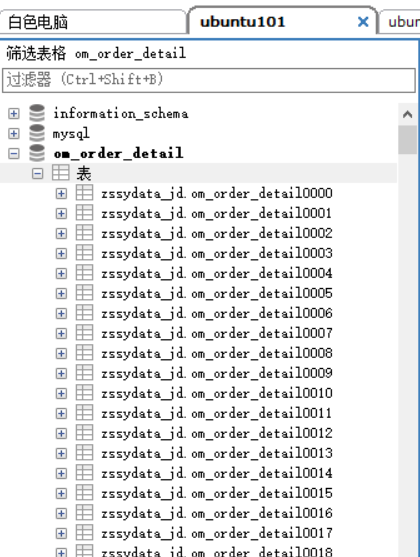
本来打算用mysql分库分表进行三院数据处理(最大的一张表有两亿数据)。计划是三台ubuntu每台负责一到两张大表。每个表单独建立一个库,按照用户ID分别在库中做分表功能
 |  |  |
用的是etl工具kettle进行数据读取再入库的(*记得使用etl工具时需要进行数据分片把一个大库分成几个部分然后输入到其他库上,否则一个任务没完成也要重新开始)
细节:
第一:若单纯做数据迁移查询,数据库引擎可食用Myisam,没有innodb的行锁与机制,然而数据写入速度提高
第二:关闭mysql binlog 因为bin_log 会把数据库的写入异步保存为一个二进制文件,供slave库执行同步 ,其实会稍微影响效率
my.cnf 在[mysqld]添加 skip-log-bin 重启mysql
执行查询SHOW VARIABLES LIKE “log_bin” Value为OFF即 关闭了log_bin
第三:绝对不可以将某一个张表分往某一台服务器上。而是要把一张表水平分到多台服务器上 否则当执行某一业务(需要查询某张表时)所有网络访问和数据库连接,只落在同一台服务器上完全起不到多服务器集群的作用。(我应该前300张表在 ubuntu1 中间300张表在ubuntu2 最后300张表在ubuntu3)